


研究背景
随着企业数据分类分级建设工作的推进,非结构化数据由于其内容格式、存储格式、文本构成等复杂多样,成为企业在数据识别和分类分级工作中面临的又一座高山。
基于在电信、政务等领域的项目实施经历,证件影像类数据是一种常见、高价值、高敏感度的非结构化数据,其通常以图片的形式进行存储和流转。针对图片类数据的识别,业内通常采用OCR技术提取图片内文本信息,然后再针对文本信息进行识别匹配。但在实际项目中,图片质量通常参差不齐,大部分图片的清晰度无法达到OCR识别的最佳效果要求;同时,企业出于业务要求和安全考虑,通常会对证件类图片添加水印或文本标签,进一步干扰了OCR的识别效果。因此,常规的OCR算法已经无法满足证件类图片的识别要求,研发一套抗干扰内容能力强、准确度高的OCR算法对于当前的业务场景变得越来越重要。

(图1)项目图片实例
核心优势
到目前为止,OCR的发展已经有了非常多的积累,市面上开源的OCR项目对于通用业务场景下的文本识别有着不错的识别速度和识别准确率。但是,对于特定场景下的文本识别效果就差强人意。因此,为了满足特定业务需求,企业研究人员还需要对OCR算法做针对性的二次开发和改良。
思维世纪通过对现有的数据源进行数据质量调研,针对性地开发了一套适用于现有证件图片的OCR算法模型,该模型已经在思维世纪的数据资产测绘管理系统中稳定运行。运行结果显示,该算法在速度和精度上都保持着较高的性能。
1、速度方面
▶在测试环境下识别一张证件类图片花费1s左右(不同的证件图片耗时略有差异)。
2、精度方面
▶在对带干扰内容的图片,该算法依然保持着98%以上的准确率,完全满足当前的业务需求。
模型方案
00
模型整体架构
模型整体流程图如下:
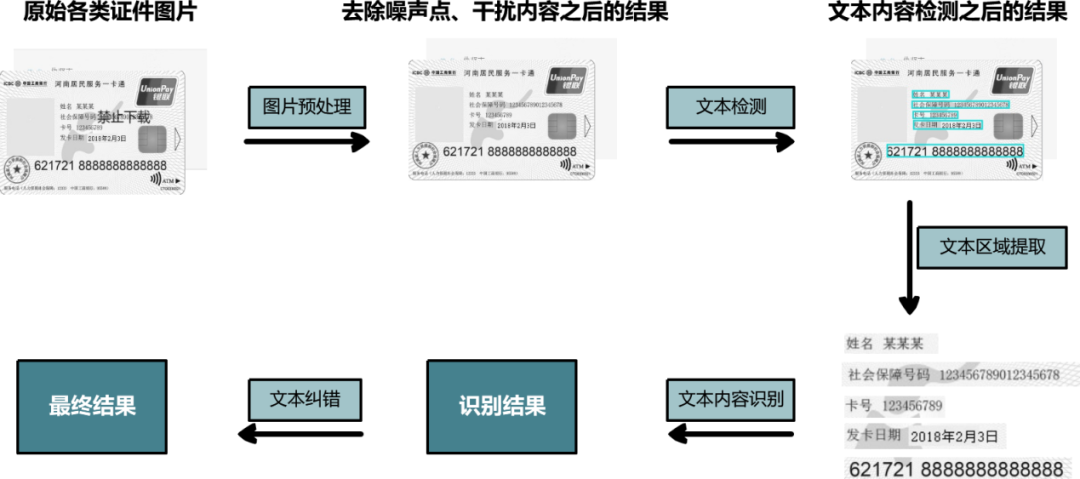
(图2)模型流程图
注:流程中的证件图片均来源于工具生成的示例数据(下同)
●● 第一部分是图片预处理模块。该模块的主要功能包括图片灰度化、图片二值化、模糊图片超分辨率重构、图片干扰内容去除(印章、水印等)等。
●● 第二部分是关键文本定位模块。该模块主要负责定位证件图片中的关键文本(例如社保卡上面的姓名和社会保障号码)的位置。
●● 第三部分是文本识别模块。该模块使用CRNN+CTC文本识别模型进行文本识别。
●● 第四部分是文本纠错模块。该模块的作用是利用规则和算法对识别出的各个敏感元素进行校正,最大程度地提高识别的准确率。
01
这一模块是该模型的核心模块。通过对待识别证件图片做数据质量调研发现了两类问题,一类问题是证件图片质量参差不齐,清晰度差别较大;另一类问题是有许多证件图片都添加了其他干扰信息,比如印章,水印等,这些干扰信息会影响到最终提取出的文本内容的准确率。
基于以上两点,图片预处理模块结合了传统计算机视觉算法和深度学习算法的方案,通过腐蚀膨胀、二值化等传统方法去除图片中的噪声点,再通过对抗生成网络来重构图片的分辨率和去除图片中的印章、水印等。图3展示了对身份证图片去除干扰文字之后的结果。
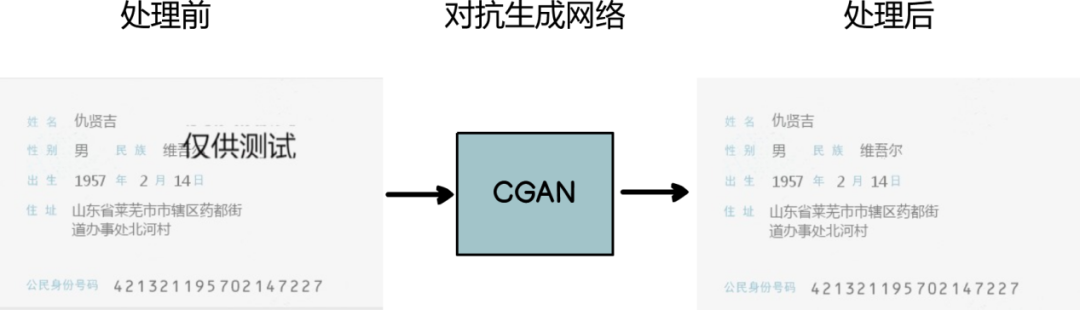
(图3)CGAN预处理图片
02
文本检测就是要定位图片中的文字区域,然后通常以边界框的形式将单词或文本行标记出来。传统的文字检测算法多是通过手工提取特征的方式,特点是速度快,简单场景效果好,但是面对自然场景,效果会大打折扣。当前多是采用深度学习方法来做。
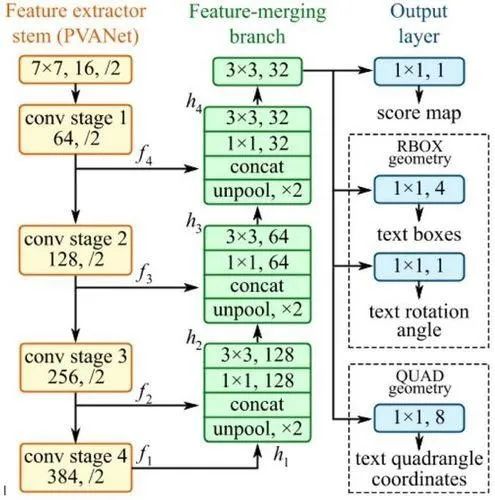
(图4)EAST算法结构图
注:图片引用于网络
我们在文本检测模块采用了EAST算法(图4)作为文本检测算法,该算法是基于目标检测的方法,其优点是能够高效、准确地检测出图片中任意方向和矩形形状的文本或文本行。为了确保最终文本检测结果的准确性和有效性(只检测有价值的文本内容),我们在构造文本检测模型训练数据的时候,对真实的文本检测框做了筛选,只保留了那些需要被检测到的文本框。图5展示了对社保卡图片的文本检测结果,文本检测算法只检测出了姓名、社会保障号码、卡号、发卡日期这些有价值的文本。
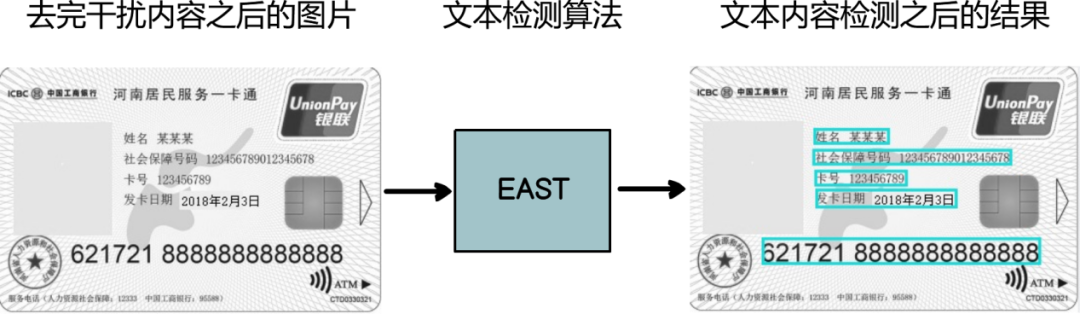
(图5)EAST文本检测结果
03
在检测到图片中的文本区域之后,就需要使用文本识别模型识别文本区域中的文本内容。我们采用CRNN+CTC模型(图6)作为文本识别模型。其优点是识别准确率高、能够进行端到端的训练、输入长度可变,可以识别不同长度的文本、识别速度快。
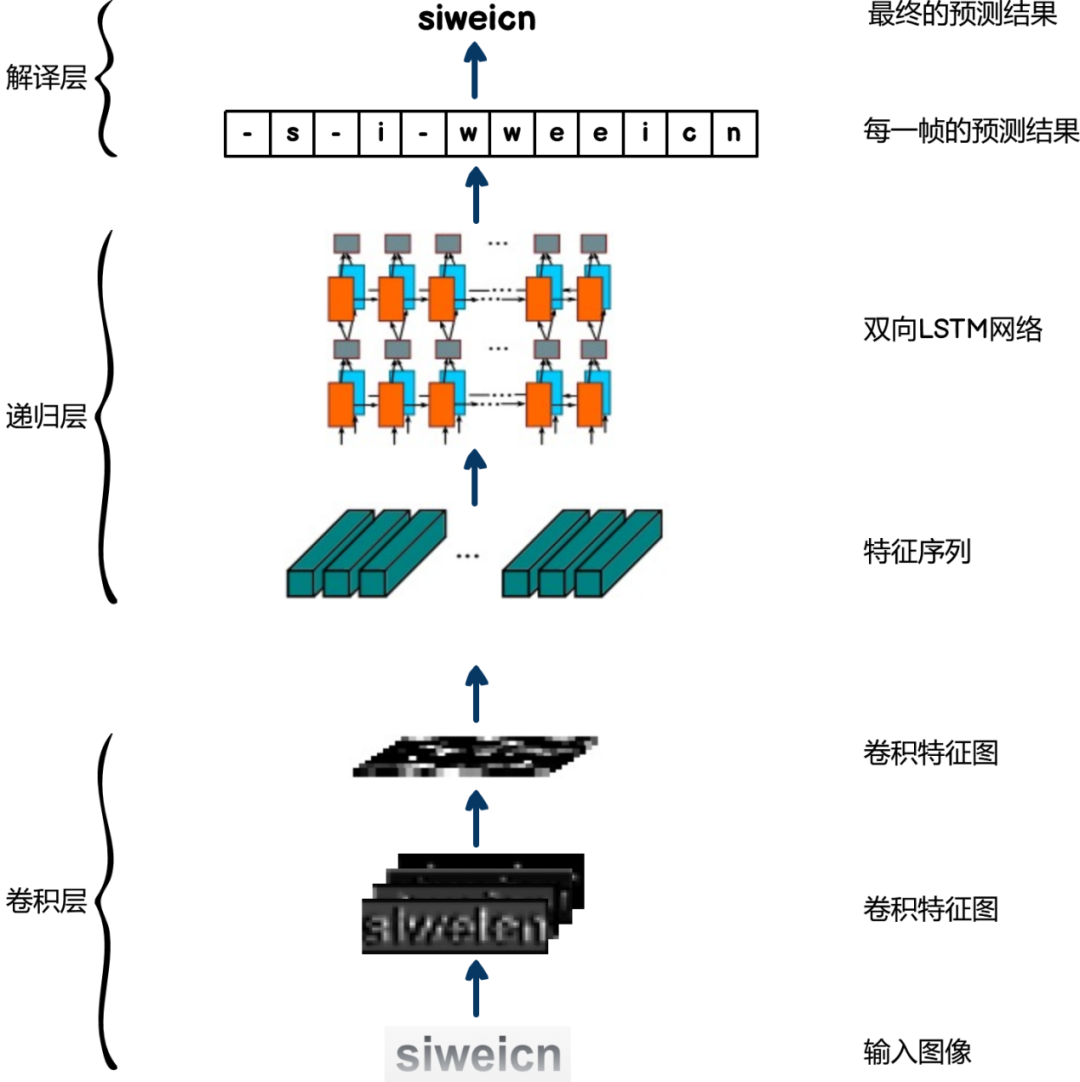
(图6)CRNN+CTC模型
● 卷积层:使用CNN提取上一阶段检测出的关键文本图片的高维特征。
● 递归层:使用双向LSTM对图片特征序列进行预测。
● 解译层:使用CTC,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。
04
为了进一步提高文本识别的准确率,需要对文本识别模块识别的结果做进一步地修正。对于证件图片,思维世纪的OCR算法模型采用了规则纠正法和最大字符匹配法进行纠正。规则纠正法主要应用于那些有特定规则的元素,如18位的身份证号是由地址码、出生日期码、顺序码、和校验码组成;组织机构代码也有校验码来校验该组织机构代码是否合规。另外,对于地址、民族等信息则可以通过最大字符匹配法进行纠正。运行结果证明,文本纠正算法对于身份证、户口本等证件图片的识别文本纠正效果明显。
结语
这套OCR算法模型的各个模块相互独立,灵活性好,每一个模块都能单独分离出来应用于其他场景。另外,我们在该模型的核心模块(图片预处理模块)做了大量的工作,基于大量的携带不同干扰内容的图片训练出一个通用性较强的图片预处理模型,即使遇到其他一些干扰内容,该模型也能较好地完成图片的预处理工作,为后续文本内容识别做好铺垫。目前,该算模型已经在思维世纪自主研发的数据资产测绘管理系统中集成,并在部分项目中落地应用。
— 往期回顾 —



