


研究背景
随着信息技术和人类生产生活交汇融合,互联网中的数据海量增长,互联网业务中频繁出现个人信息泄露、信息篡改等安全事件,个人信息数据常被被不法分子想办法窃取、篡改、贩卖、从中牟利。大量互联网业务被不法分子注入不良信息网页和被篡改的网页散落在互联网中。数据安全的风险日益加大,国家和企业都对防范数据安全风险也日益重视。依据国家监管部门和集团公司相关要求,需要分析互联网上的数据并将获取到的不良信息网页数据进行整改,首先要将数据从网络中获取下来,这就需要使用到网络数据爬虫技术。
网络数据爬虫,又称为网络数据蜘蛛、互联网机器人等。它通过爬取互联网上网站的内容来工作。它是用计算机语言编写的程序或脚本,用于自动从Internet上获取任何信息或数据。爬虫扫描并抓取每个所需页面上的某些信息,自动实现对目标站点和目标信息的批量获取,包括信息采集、数据存储、信息提取。在利用爬虫技术时应采用搜索引擎的爬虫来对网页上的信息进行搜集和存储,应当严格遵守Robots协议规范爬取网页数据(如URL)。禁止未经合法授权或超越授权去侵入它人的网站服务器,确保爬虫程序不会突破或绕开网站服务器的防护措施。
爬虫技术手段
爬虫通用架构如下:
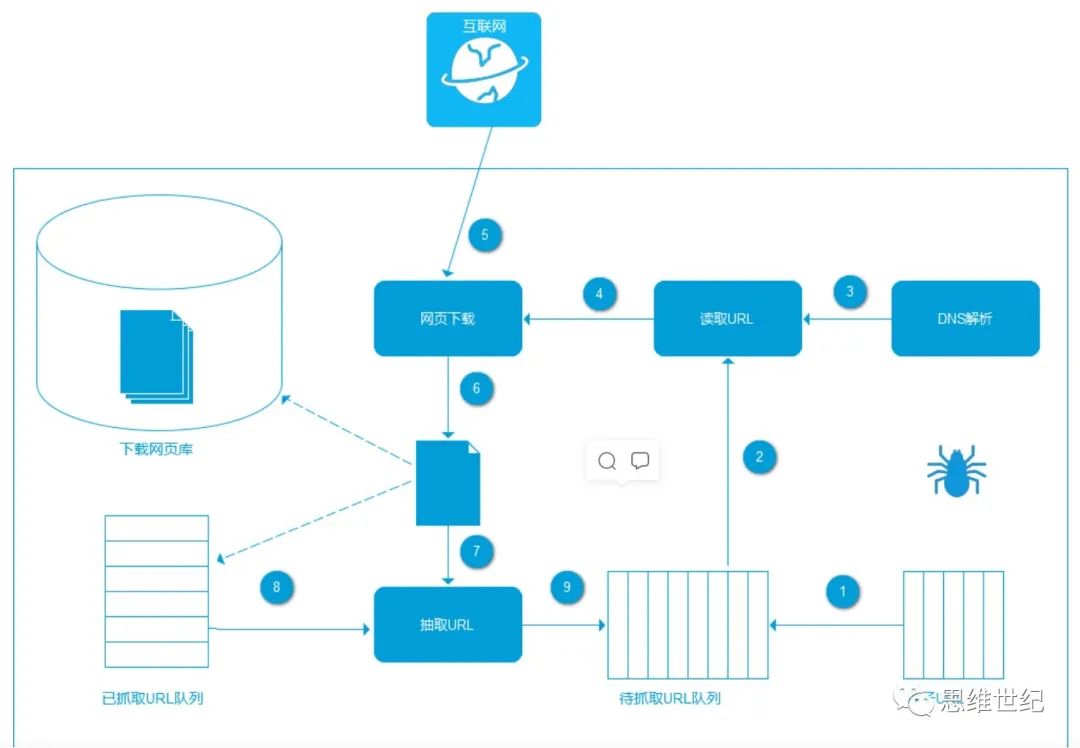
爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面的下载。对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取队列中,这个队列记录了爬虫系统已经下载过的网页URL,以避免系统的重复抓取。对于刚下载的网页,从中抽取出包含的所有链接信息,并在已下载的URL队列中进行检查,如果发现链接还没有被抓取过,则放到待抓取URL队列的末尾,在之后的抓取调度中会下载这个URL对应的网页。如此这般,形成循环,直到待抓取URL队列为空。
通用爬虫
通用爬虫又称全网爬虫,它将爬取对象从一些种子 URL扩充到整个Web上的网站,主要用途是为门户站点搜索引擎和大型Web服务提供商采集数据。
聚焦爬虫
聚焦爬虫,又称主题网络爬虫,是指选择性地爬行那些与预先定义好的主题相关的页面的网络爬虫。
增量式爬虫
增量式网络爬虫是指在具有一定量规模的网络页面集合的基础上,采用更新数据的方式选取已有集合中的过时网页进行抓取,以保证所抓取到的数据与真实网络数据足够接近。
表层爬虫
爬取表层网页的爬虫叫做表层爬虫。表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的Web页面。
深层爬虫
爬取深层网页的爬虫就叫做深层爬虫。深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。
数据防护措施方案
不法分子利用恶意爬虫不遵守网站的robots协议,对网站中某些深层次的、不愿意公开的数据肆意爬取,其中不乏个人隐私或者商业秘密等重要信息,并有可能给对方服务器性能造成极大损耗。未经过网站服务器的合法授权去抓取数据会干扰网站的正常运营,而非正规爬虫自动持续且高频次地对网站服务器发起请求,服务器负载飙升,同一时间大量的爬虫请求会让网站服务器过载或崩溃,尤其是中小网站可能会面临网站打不开、网页加载极其缓慢、甚至直接瘫痪的情况。
Uswe-Agent 反爬虫
User-Agent是请求头的一部分,在用户请求网站时会告诉网站服务器,网站服务器可以通过请求头参数中的 User-Agent 来判断请求方是否是浏览器、客户端程序或者其他的终端,如果是通过爬虫方式请求则为默认的请求头信息,直接过滤拒绝访问,如果是用户浏览器,就会应答。
在网站服务器设置User-Agent,添加指定的User-Agent请求头信息,User-Agent存放于Headers中,网站服务器就是通过查看Headers中的User-Agent字段中的值来判断是谁在请求访问网站。当用户或者爬虫程序请求访问网站时网站服务器会自动的去检测连接对象,如果检测到请求头中未包含指定的User-Agent的话,网站本身的反爬虫程序就会识别出你是通过爬虫程序在访问网站,网站服务器会判断是非法请求,从而拒绝访问 。如果检测对象的User-Agent为指定的请求头信息则接受访问。
黑名单策略
在网站服务器中配置黑名单策略,当请求方发起请求后网站服务器进行识别、只要编程语言出现在黑名单策略中,都视为爬虫,对于此类请求可以不予处理或者返回相应的错误提示。

User-Agent访问
网站服务器后台对访问进行统计,如果单个User-Agent访问超过指定阈值,予以临时封锁或永久性封锁。
单个IP访问
网站服务器后台对请求访问的IP进行统计,如果单个IP访问超过指定阈值,予以临时封锁或永久性封锁。
结 语
当前,互联网数据作为新型生产要素,正深刻影响着国家经济社会的发展。大量恶意爬虫窃取网站核心数据,应当采取数据防护措施手段,保障数据得到有效保护和合法利用,并使数据持续处于安全状态的能力以及保障网站服务器的正常运转和降低服务器的压力与运营成本。通过反爬虫技术手段对网站数据进行防护,避免被那些不遵守网站robots协议的恶意爬虫肆意高频次的从网站爬取个人信息数据、企业非公开和国家重要等数据。
注:使用网络爬虫技术有风险,应当严格遵守以下规则
在网站服务器方合法授权的情况下进行善意爬扫;
使用善意爬虫严格遵守网站服务器方设置的robots协议规则范围爬取网页数据;
禁止爬取含有个人隐私的数据;
禁止爬取含有知识产权的数据;
禁止高频次恶意频繁请求访问网站。
往期回顾
嘶吼专访 | 思维世纪董事长章明珠:蓄势待发,专攻数据安全赛道的挑战者



